区域感知动态卷积论文笔记
论文地址:https://arxiv.org/pdf/2003.12243.pdf 该论文提出了DRConv。传统的卷积结构由于权值共享,所以只有通过增加网络宽度和深度来增加网络捕获的图像特征,这种方法会浪费大量的算力。本论文提出的DRConv构造出了一个“智能通道过滤器”,且该过滤器即实现了类似local conv 1的不同像素不同权重的效果,又保证了网络存在平移不变性,同时整个网络的复杂度并没有提升,同时该网络在几大任务图像任务 2中的表现都好于传统网络 3。
Introduction
由于现在主流的卷积神经网络都是权值共享的,所以每一层能够抽取的信息是有限的,如果想要增加抽取的信息,只能通过增加网络的宽度 4和深度 5来实现。
这种传统的方式有很多的缺点,比如:
- 计算量大,计算效率低
- 这会造成优化困难,网络调试变得十分复杂
为了解决这一问题,一些学者提出了local conv 6 7 这种对每个像素都有不同权重的做法虽然取得了不错的效果,计算复杂度也没有显著的增加,但是它仍然有两个致命的缺点:
- 由于取消了权重共享,导致整个网络的参数量非常大,占用空间也很高。
- 由于失去了平移不变性,这使得该网络不能做分类任务。
除此之外,对于不同的样本local conv仍然共享滤波器,这使得该网络对特殊的样本样本不敏感 8。
为了克服上面的问题,作者提出了DRConv,其执行过程如下: 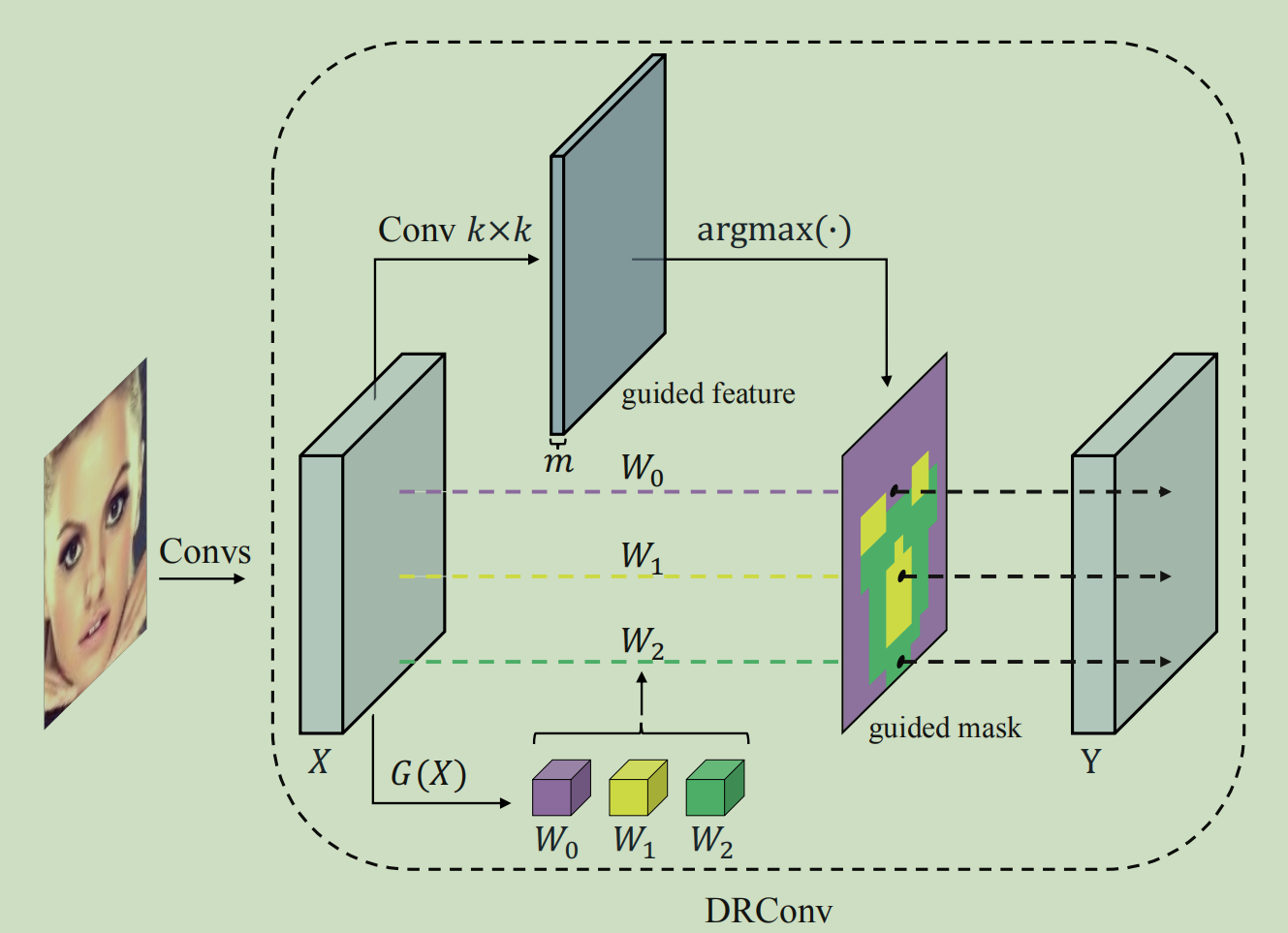
首先,通过标准卷积生成guided feature,根据guided feature将整个图像分成多个区域,卷积核生成模块\(G(X)\)根据输入图片动态生成每个区域对应的卷积核,且在每个区域的卷积核是权重共享的,保证了平移不变性。
DRConv可以根据不同的区域匹配不同的卷积核,由于卷积核是动态生成的,所以它要比local conv参数少很多,同时其计算复杂度和标准卷积基本一致。
为了验证效果,本文对比了当前效果较好的网络结构,并对卷积常见的任务都做了对比。
Related Work
Spatial Related Convolution
最早的空间相关的卷积网络是local conv,思路很简单,对于每个像素,均使用独立的非共享的滤波器。这种网络对于不同的区域有不同的特征分布的时候(如人脸识别)有很大的应用空间,比较典型的代表就是DeepeFace和DeepID系列网络
在目标检测方面,R-FCN使用基于区域的全卷积去提取局部表征。
除了上面的两个卷积网络结构外,一些模型则通过改变空间特征来更好地模拟语义变化,STNet(Spatial Transform Networks)可以通过学习来转动特征图,但是它非常难训练。ACU(active convolution unit)没有固定的卷积单元形状,它的形状(偏移量)是在训练中改变的。  Deformable Convolutional Network 进一步使得相对位移更加动态
Deformable Convolutional Network 进一步使得相对位移更加动态 
Dynamic Mechanism
由于网络对数据的依赖性很强,动态机制也应运而生,首先是SKNet , 该网络通过抽取不同感受野的特征提升了网络的精度。使用Attention机制的SENet 则通过动态给各个通道加权来提升网络的精度。
在动态权重方面,CondConv 通过对多个权重进行动态的线性组合来获取最终的权重。
对于不同的样本调整特殊的卷积核也是动态机制的运用,Deformable Kernels 通过学习卷积核的偏移来对原卷积进行重采样,而不改变输入数据。

NonLocal 通过计算每个像素点和整体像素点的关系来实现完整的感受野操作。
Dynamic Region-Aware Convolution
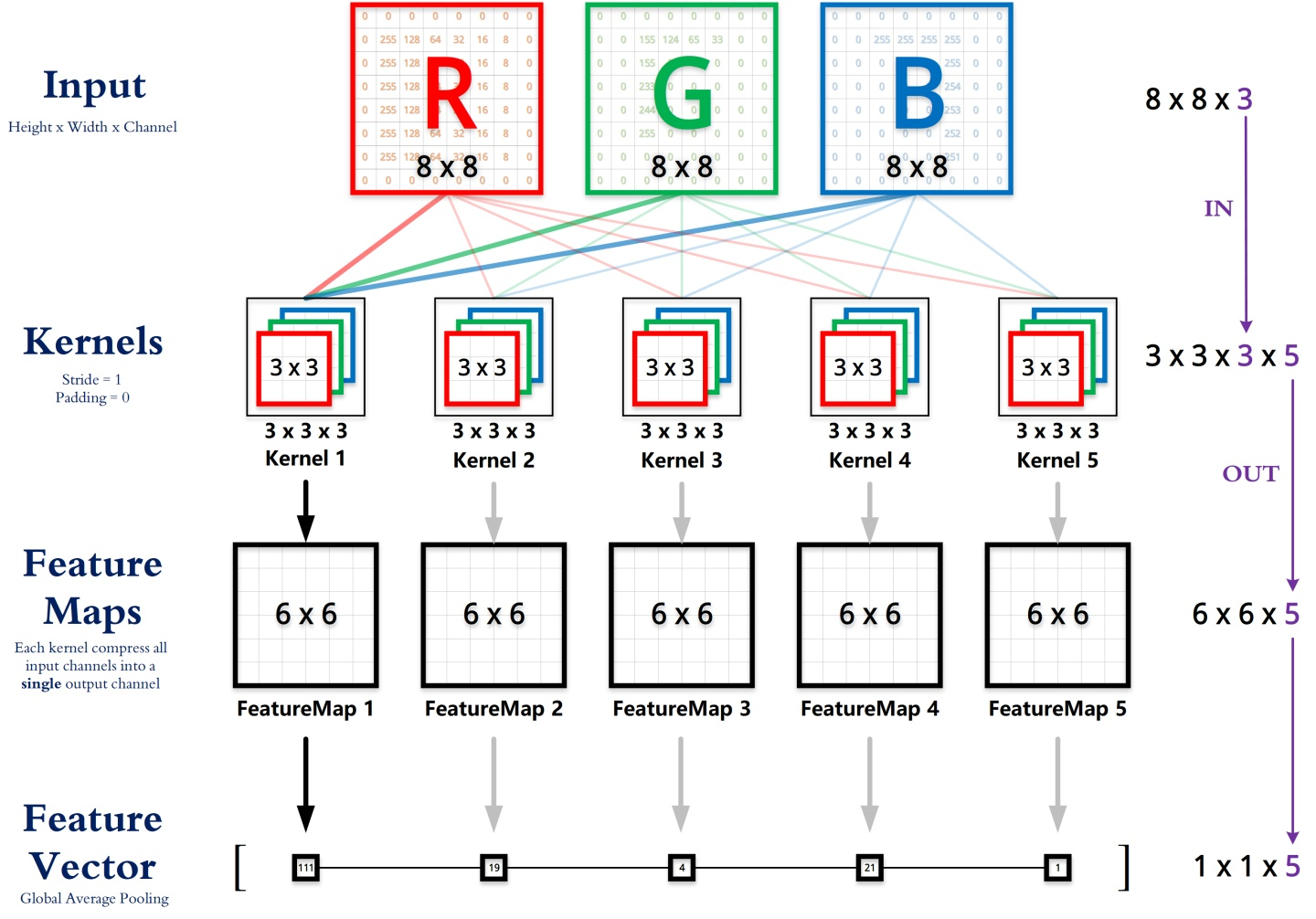
首先为了对比,先看一下标准卷积的公式:
\[Y_{u,v,o}=\sum_{c=1}^C X_{u,v.c} \ast W_c^{(o)} \qquad (u,v) \in S\]
对于标准卷积,定义输入\(X\in \mathbb{R}^{U \times V \times C}\),空间维度\(S \in \mathbb{R}^{U \times V}\),输出\(Y \in \mathbb{R}^{U \times V \times O}\),权重\(W \in \mathbb{R}^C\),输出的第o个channel的计算如上,\(\ast\)为二维卷积操作。
为了方便理解,附上一张卷积的计算过程图:
然后我们再看看local conv的计算:
\[Y_{u,v,o}=\sum_{c=1}^C X_{u,v.c} \ast W_{u,v,c}^{(o)} \qquad (u,v) \in S\]
这里我们定义非共享权重为\(W \in \mathbb{R}^{U \times V \times C}\),输出的第o个channel公式如上,其中\(W_{u,v,c}^{(o)}\)表示位置\((u,v)\)上的独立非共享卷积核,即卷积在特征图上移动时,每次更换不同的卷积核。
最后我们看一下guided mask的计算公式:
\[Y_{u,v,g}=\sum_{c=1}^C X_{u,v.c} \ast W_{t,c}^{(o)} \qquad (u,v) \in S_t\]
结合以上公式,定义guided mask\(M=S_0, \cdots , S_{m-1}\)用来表示空间维度划分的\(m\)个区域,\(M\)根据输入图片的特征进行提取,每个区域\(S_t (t \in [0, m-1])\)仅使用一个共享的卷积核。定义卷积核集\(W = [W_0 , \cdots , W_{m-1}]\),卷积核\(W_t \in \mathbb{R}^C\)对应于区域\(S_t\)。输出的每个channel的计算如上,即卷积在特征图上移动时,每次根据guided mask更换对应的卷积核。
Learnable guided mask
guided mask决定了卷积核在空间维度上的分布情况,其重要性可想而知,为了能适应不同的样本,该模块必须设计成可以通过损失函数进行反向传递而进行优化。下面讨论一下如何对该模块进行反向传递。
首先,guided mask 上的值的计算公式如下:
\[M_{u,v}=argmax(F_{u,v}^0 , F_{u,v}^1 , \cdots , F_{u,v}^{m-1})\]
其中,F我们称之为guided feature,M为guided mask,上面的公式表示M上每个位置\((u,v)\)的计算公式,\(F_{u,v}\)表示位置\((u,v)\)上的guided feature向量,其实上面的公式就是指示M个feature map中位置\((u,v)\)上的最大值的下标。
这里有一个问题,就是argmax函数不可导,无法获得梯度,这样就没办法做反向传播,为了解决这一问题,作者用softmax来近似的替代argmax。
forward propagation
guided mask的前向传播比较简单:
\[\hat{W_{u,v}}=W_{M_{u,v}} \qquad M_{u,v} \in [0, m-1]\]
\(M_{u,v}\)表示guided feature在\((u,v)\)位置上的最大下标,\(W_{M_{u,v}}\)是m个卷积核集中的一个。
back propagation
这里我们使用softmax来代替之前的one hot 编码,以方便进行反向传播:
\[\hat{F_{u,v}^j} = \frac{e^{F_{u,v}^j }}{\sum_{n=0}^{m-1}e^{F_{u,v}^{n}}} \qquad j \in [0, m-1]\]
定义\(\hat{F}\)来代替guided mask中的one hot表示,如上,在channel维度上做了softmax,以期望\(\hat{F_{u,v}^j}\)近似的接近0和1。
由于对onehot无法求导,我们对上述公式进行反向传播:
\[\nabla_{F_{u,v}} \pounds = \hat{F_{u,v}} \odot ( \nabla_{\hat{F_{u,v}}} \pounds - 1<\hat{F_{u,v}} , ( \nabla_{\hat{F_{u,v}}} \pounds>)\]
这个公式看起来有些复杂,其实本质就是softmax反向求导公式,首先softmax的导函数为\(y(1-y)\)。上面公式中,\(\nabla_{\hat{F_{u,v}}} \pounds\) 表示loss对\(\hat{F}\)求导,我们提出这一个公因子就会发现其本质就是softmax求导再乘于loss对\(\hat{F}\)求导。这也正是反向传播的规律。
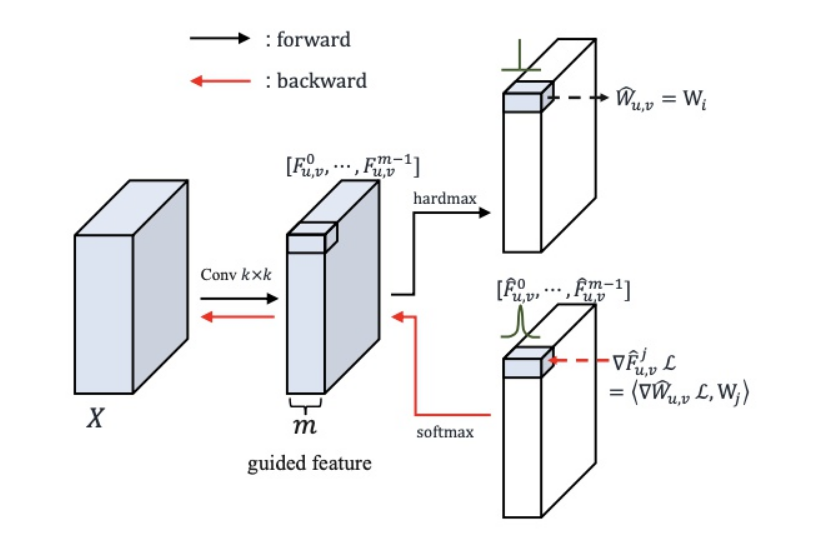
上图中的反向求导公式就是前向传播中公式的反向传播
Filter generator module
这部份我们主要讨论多个卷积核是如何生成的,如下图:
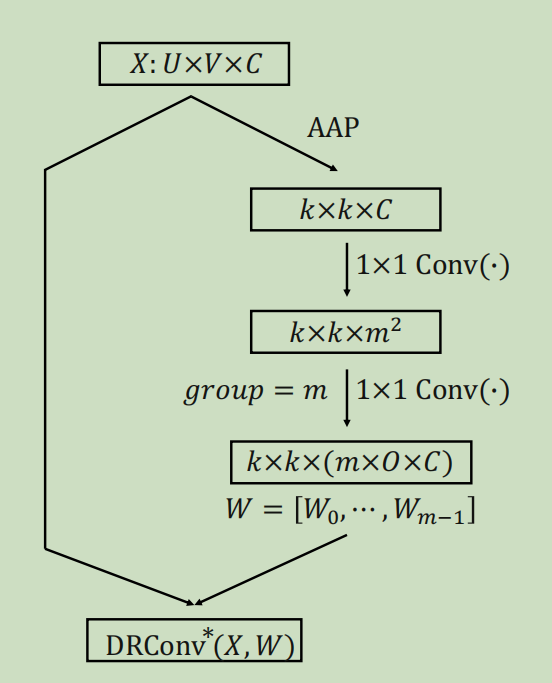
过程并不复杂,其实就是通过了两个一维卷积最后分成\(m \times C\)个channel,只需要注意第一个一维卷积使用\(sigmoid(\bullet)\)进行激活,而第二个不使用激活函数即可。
Experiments
Classification
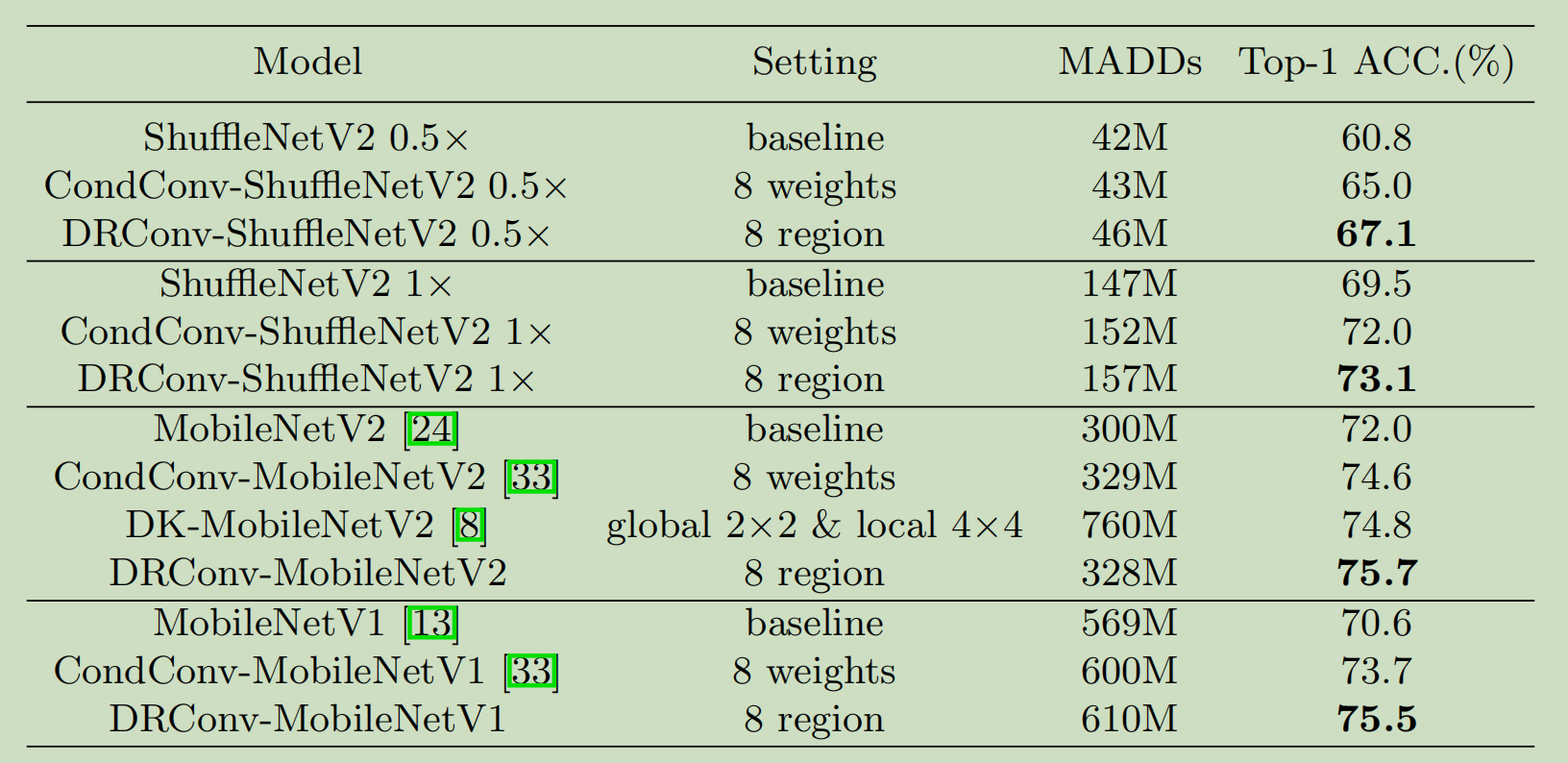
Face Recognition
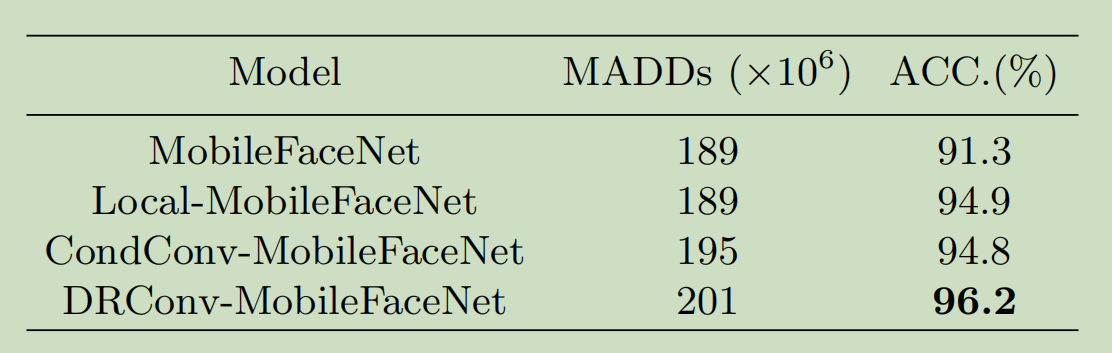
COCO Object Detection and Segmentation
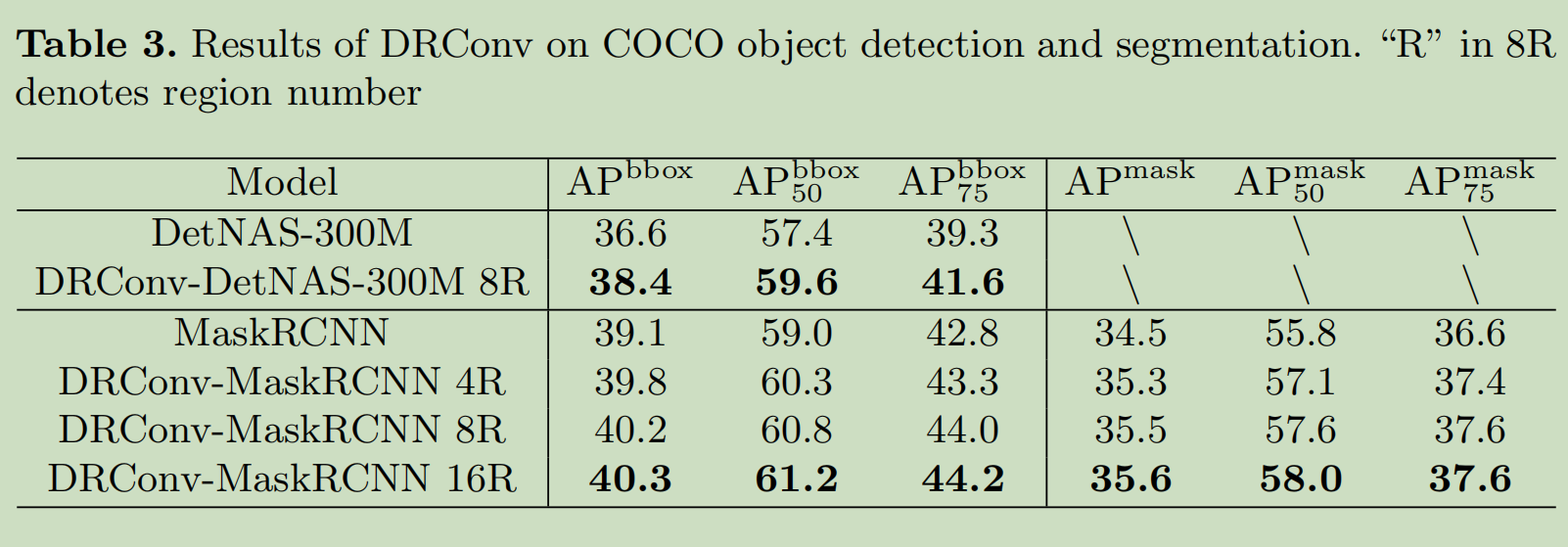
Ablation Study
这一部分通过可视化来解释为什么这样做有用,以及使用什么参数比较好。
Visualization of dynamic guided mask

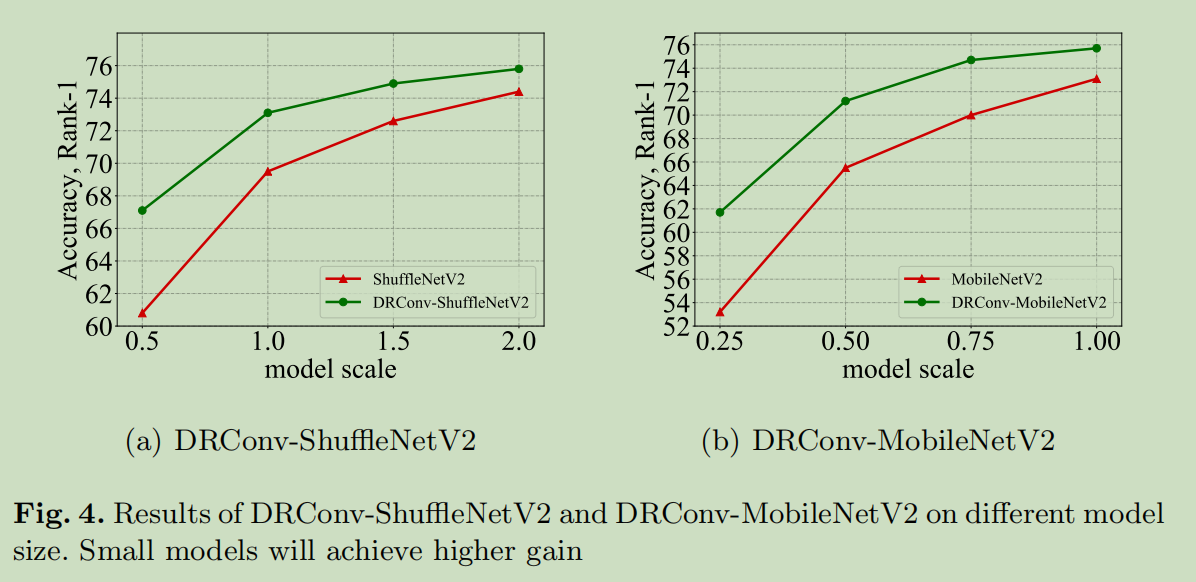
Different model size
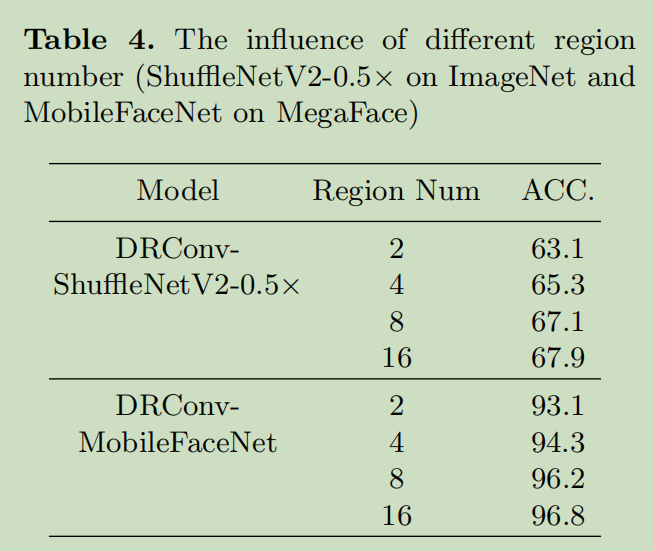
Different region number
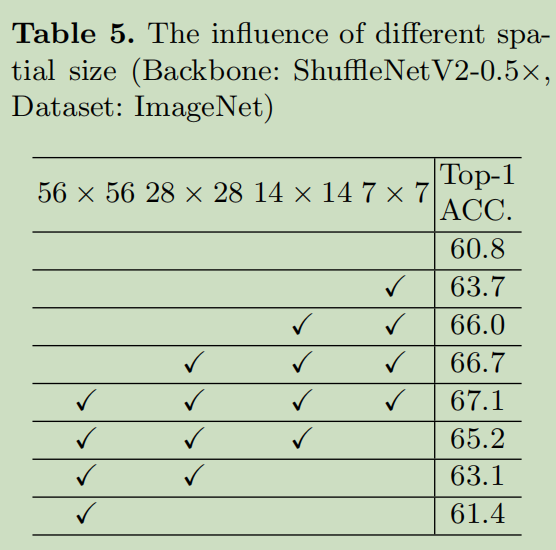
Different spatial size
对每个像素都有权重,这样做的好处是可以充分的学习图像的特征↩
分类、人脸识别、目标检测、语义分割↩
使用ImageNet数据集,Mobile Net、ShuffleNetV2, etc.↩
增加每次抽取的信息量↩
增加抽取信息的次数↩
Gregor, K., LeCun, Y.: Emergence of complex-like cells in a temporal product network with local receptive fields. arXiv preprint arXiv:1006.0448 (2010)↩
Taigman, Y., Yang, M., Ranzato, M., Wolf, L.: Deepface: Closing the gap to humanlevel performance in face verification. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1701{1708 (2014)↩
比如在面部识别和目标检测种,对于不同姿势或者角度的图像↩