核心问题:如何用一个vector表示单词?
1-of-N encoding
这是最简单的做法,相当于对所有的文字做了一个onehot编码,也就是用一个长度为N(N表示单词的个数)的向量来唯一的表示一个单词。
1-of-N encoding 但是这种方法无法表达各个单词之间的关系,比如dog和cat都是动物,解决方法是给他们再做分类
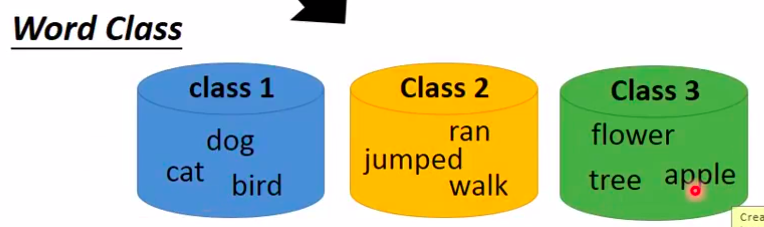
即使这样,这不能表达多个类别之间的关系。比如class1和class2之间其实是有关系的,因为动物是可以做跑跳的,显然这种硬分类也无法完全表达信息。
Word Embedding 把每一个Word都project到一个高维空间中去,这里的高维空间要比N低多得多。
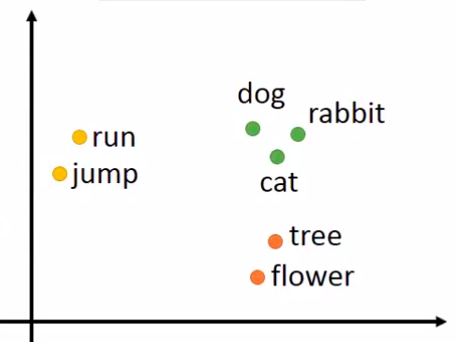
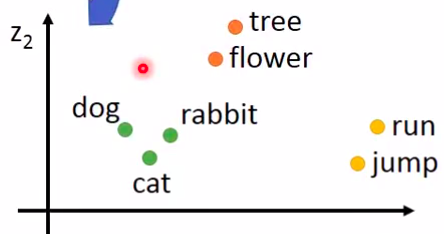
上图中各个点的关系可以通过在高位空间中的距离或者其他的指标来表示,也可以根据不同的标准来分类。
产生这种向量是非监督学习,我们只知道输入不知道输出
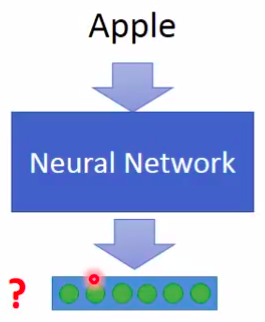
可以使用auto-encoder吗?显然是不可以的,输入的是onehot编码,其实是学不到什么东西的。- 如何通过Word Embedding 来学习上下文信息?

虽然机器不懂得蔡英文和马英九,但是根据上下文是可以把蔡英文和马英九归并成一类的。- Count based(Glove Vector)
如果单词X,Y经常在一块出现,V(X)和V(Y)就会很接近。
具体做法是让V(X)和V(Y)的内积接近于X和Y共同出现的次数\(N_{x,y}\)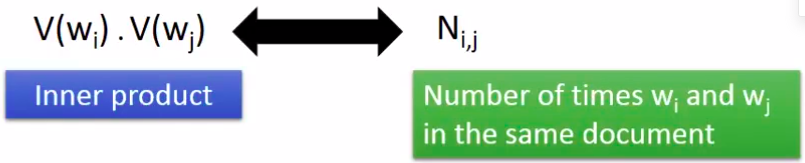
- Predition based
- 这种方法对单词的表示仍然是onehot。该方法会训练一个NN,输入是一个onehot的单词编码,输出是一个概率向量,表示某个单词紧跟着该单词的可能性大小。
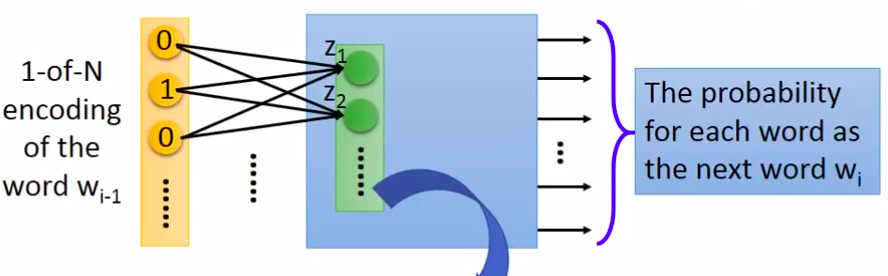
具体说来,其实是将上图中训练好的网络的第一层向量(Z)取出来作为该词汇的特征向量。
- 为什么这种方法会奏效呢?
中间的隐藏层,需要把同类或者相近的词汇投射到相同的区间。只有这样才能降低最终的loss。这种方法当然自动的考虑了上下文关系。
- 只用一个单词来预测下一个单词肯定是不太现实, 所以引入了Sharing Parameters的模型
其实就是用前N个词汇来预测下一个词汇
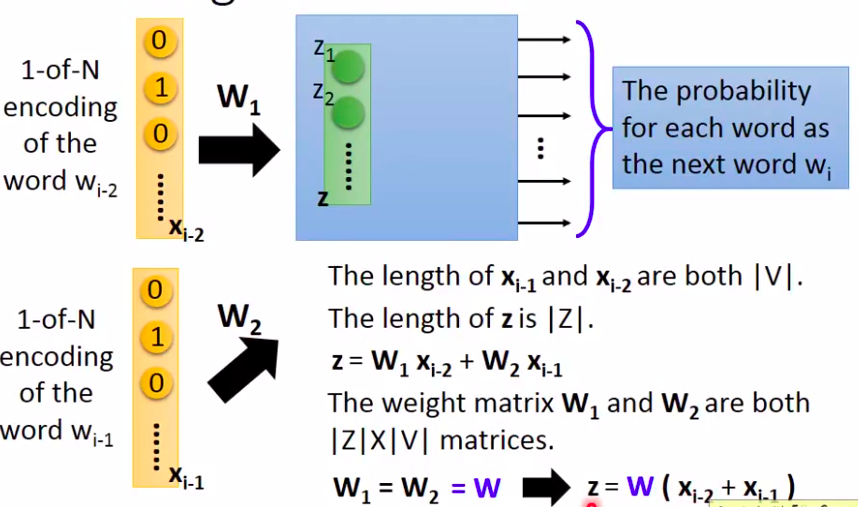
如上图,这里前N个单词的权重是共享的,对应的连接处是相同的。其原因一是为了计算方便,二是为了保证同一个单词在不同位置输入得到的特征向量是相同的(比如,就职前面的蔡英文和马英九不应该因为顺序不同而得到大相径庭的结果)。
上面的公式给了一个等价变换。要得到单词的embedding,在训练完之后,只需要乘以那个W即可得到对应的embeddding。
另外在实际训练的时候,为了保持W相同,应该做到:
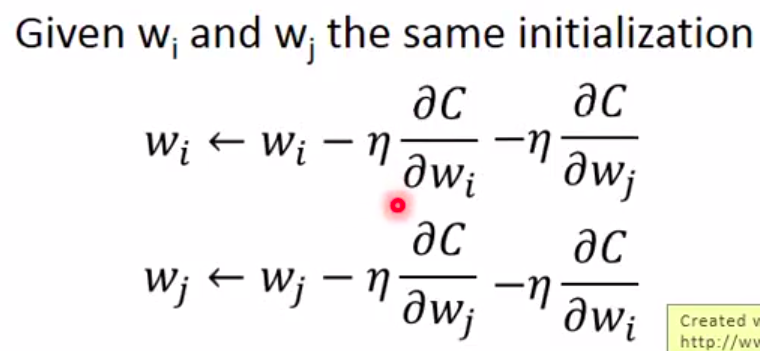
这个想法十分的巧妙,对反向传播做了小小的改动。
- 基本的训练过程
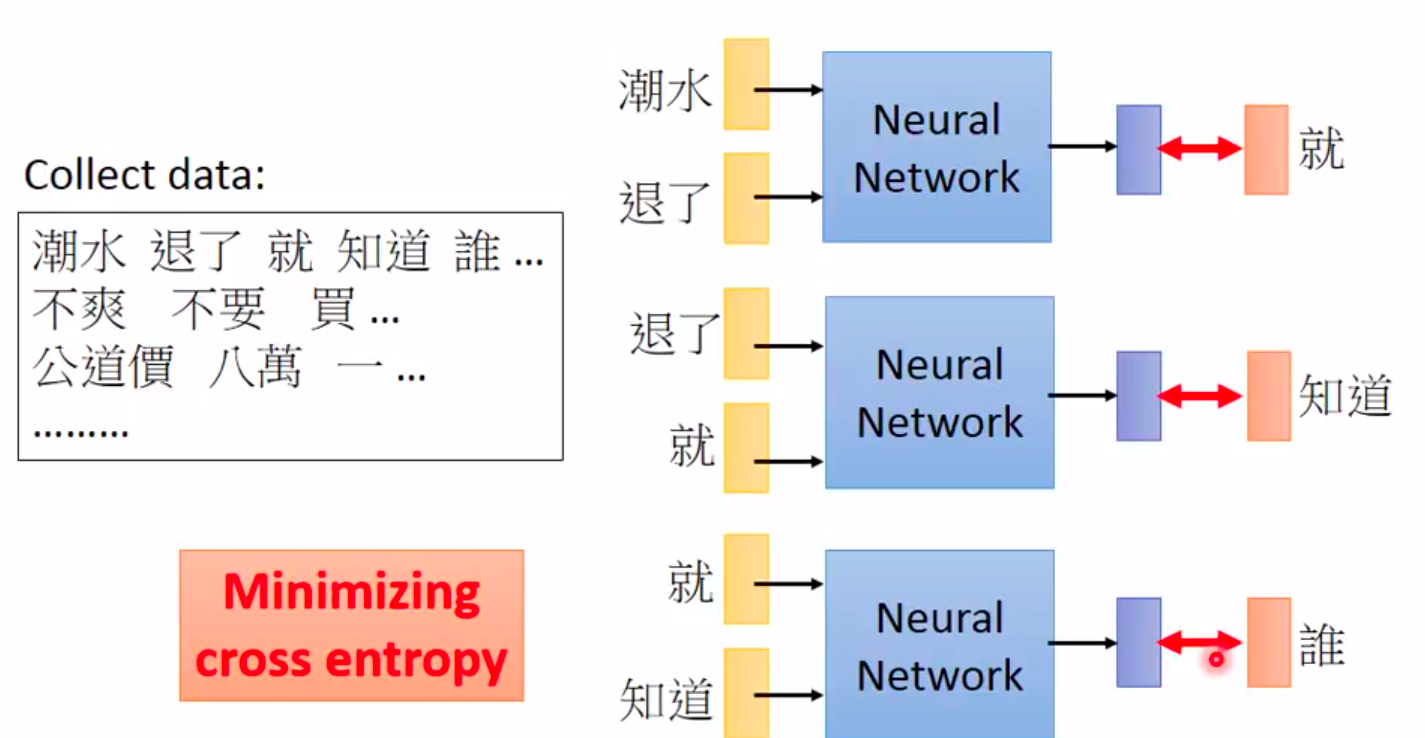
当然变形的训练有好多种,他们的优势都各有千秋:- Continues bug of word
之前是考虑上文,这里改成了考虑上下文

- Skip-gram
用中间的Word来预测上下文

- Continues bug of word
- 这种方法对单词的表示仍然是onehot。该方法会训练一个NN,输入是一个onehot的单词编码,输出是一个概率向量,表示某个单词紧跟着该单词的可能性大小。
- Count based(Glove Vector)
- 应用
对于我们训练出来的词向量,还有很多有意思的操作。- 比如对两个词向量做减法,就能得到一些规律:
\(V(hotter)-V(hot)\,\approx\,V(bigger)-V(big)\)
\(V(Rome)-V(Italy)\,\approx\,V(Berlin)-V(Germany)\)
\(V(king)-V(queen)\,\approx\,V(uncle)-V(aunt)\)
那么我们的机器就可以推测,罗马的意大利就和柏林的??一样? \(Compute\,V(Berlin)-V(Rome)+V(Italy)\)
之后就寻找最接近上述结果的词向量,就能找到答案
- 我们还可以做多语言的Word Embedding,中英文词汇翻译也可以做到
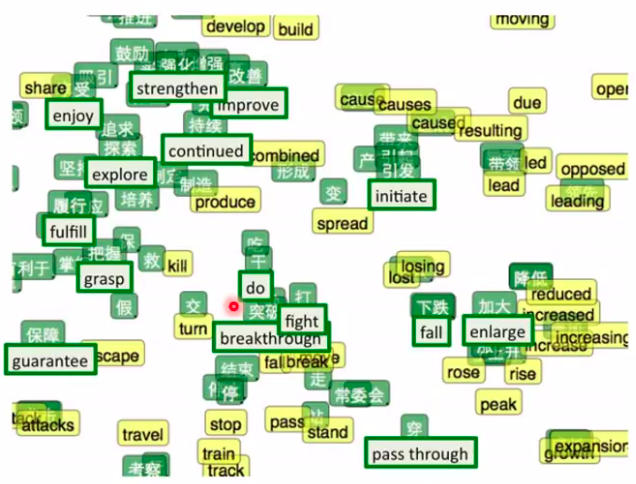
就像上面一样,我们可以学习一些对应关系,然后就可以进行翻译这种功能了。
- 除了对文字的Embedding,还可以对图像做
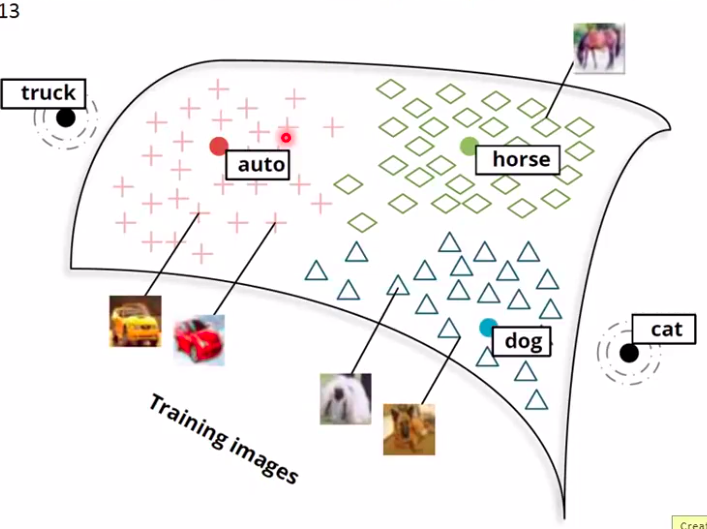
这种方式可以用来做一些分类功能,因为传统的方法无法区分新增加的类别。这种方法即使没有这一类,至少也能区别出来不是已知的类别
- 我们甚至可以多document做Embedding,最简单的方法就是对文档做词袋,然后用auto-encoder。但是词袋无法考虑语言的顺序,会失去很多的信息。 下面是一些解决办法,需要深入研究可以直接去拜读。

- 比如对两个词向量做减法,就能得到一些规律: